
很多SEO初学者对搜索引擎原理感到望而生畏,认为需要丰富的计算机知识才能理解Google原理。实际上这是种误区,就跟很多人以为学SEO一定要会代码一样。
如果你关注国外的SEO教学,你会发现很多课程会从搜索引擎原理开始讲起。这部分确实有些枯燥,但其实并不难理解。把这部分基础掌握扎实了,后续SEO学习和实践会容易很多。
所谓的“技术SEO”(Technical SEO),大部分时间也是在处理搜索引擎的抓取和收录问题,和搜索引擎原理息息相关。总之不要害怕,知航会在这篇文章中用浅显的语言把这些原理讲明白。
目录
搜索引擎是如何工作的?
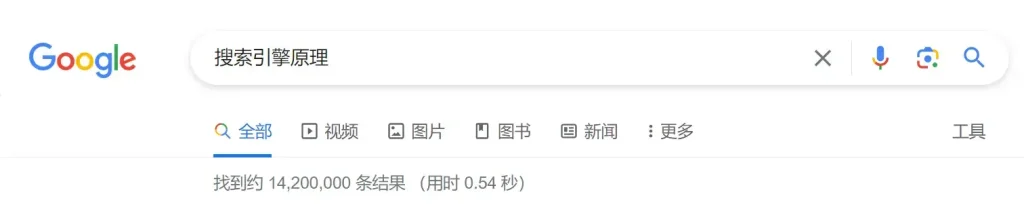
当我们在谷歌上搜“搜索引擎原理”时,谷歌一下子返回了14,200,000条结果,用时仅0.54秒。呵,这速度,比闪电还快。
这时你可能会说,谷歌是程序啊,当然有那么强大的计算能力了,所以0.54秒就能分析这么多网页了。其实这也是个误区。即使强如谷歌,也不是一瞬间就把全世界的网页研究了一遍。
还记得我们高中时,总有些学霸说自己不爱学习,结果总是偷偷复习考高分,然后再轻描淡写地说自己只是“运气好罢了”。其实谷歌也是一样的,它也是在你看不到的地方偷偷地卷起来的:所有的搜索结果都是谷歌已经编入索引并经过预处理的。当用户输入问题时,谷歌会进行语义分析,从索引中返回与用户意图相关的网页,并根据自身算法对这些网页进行排名。
总而言之,在用户进行搜索前,谷歌已经进行了很多的准备工作。而这些准备工作主要可以分为三个步骤:
- 爬行 (发现信息)
- 索引/收录 (整理信息)
- 排名 (将信息排序)
步骤一:爬行
爬行是搜索引擎工作的起点,也就是发现页面、发现新信息,然后才是将有价值的页面编入索引,进行排名。而爬行是由谷歌派出的爬虫(或者叫蜘蛛)完成的。
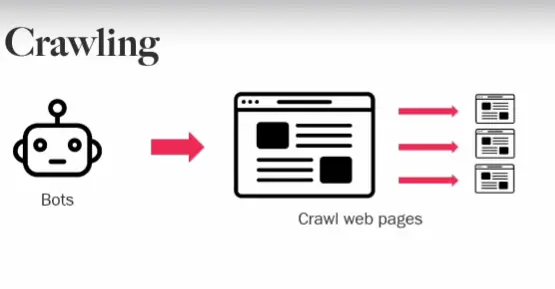
a.什么是搜索引擎爬虫?
搜索引擎爬虫(crawler)也被称为蜘蛛(spider),是一种通过不断点击链接来发现页面,并提取页面内容和元数据的程序。此外爬虫还能用来检查已发现页面是否有更新(比如页面添加了新内容,更新了内链等等)。
在爬行过程中,谷歌爬虫通过网页链接查找新网址,并将优质的新内容添加到索引中(索引环节),最后等待用户搜索内容时匹配相关的网页(排名环节)。你可能难以想象,但每天在互联网上爬行的爬虫有几十亿个! 可见搜索引擎爬虫的工作量有多大了。

b.在爬行环节,爬虫会看到什么?
在爬行环节,爬虫首先会获取的网页的HTML代码。HTML代码是网页的骨架,包括了网页的结构、网站内容、样式。通过解析HTML代码,爬虫会获取网页的相关信息:
- 网页标题
- 关键词
- 描述(meta描述)
- 内容(文本内容)
- 链接(超链接)
- 图片
- 视频
- 音频
- 其他元数据(例如作者、发布日期等)
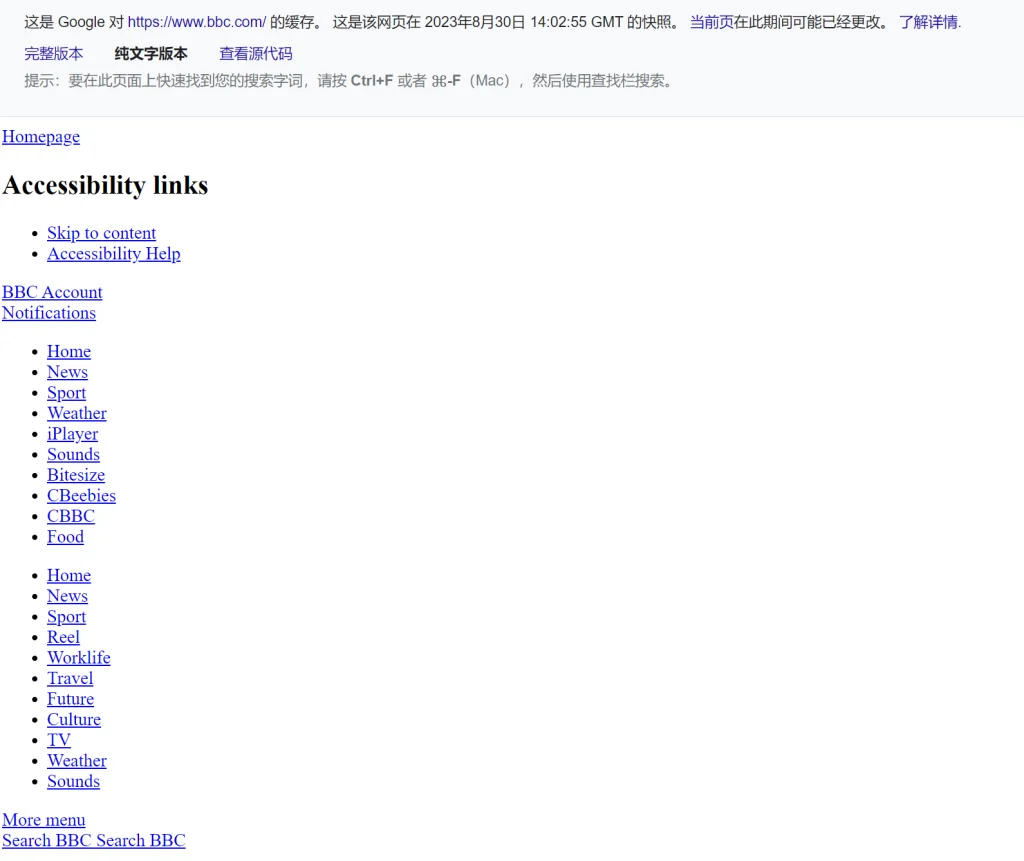
值得注意的是,爬虫来到一个网页,并不会马上执行CSS和Javascript,也就意味着爬虫第一眼看到的网页有点类似网页快照里的纯文字版本。以BBC网站举例:
- BBC首页纯文字版本
- BBC首页完整版本(需执行CSS和Javascript才能看到,也就是我们浏览器打开后看到的)
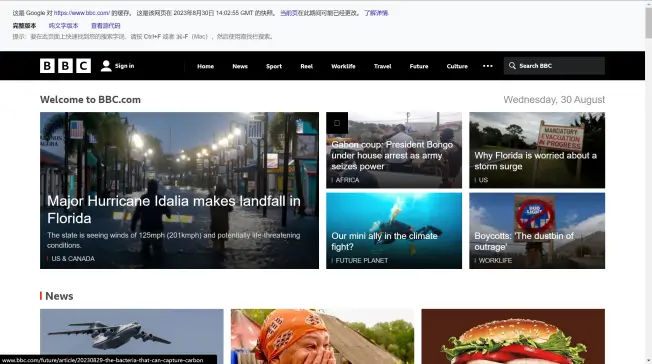
看到这你可能会问:既然爬虫爬行的阶段谷歌看不到我们网站的全貌,那什么时候会看到呢?别急,这要等到后续的渲染(Search Engine Rendering)过程才能看到。
c.为什么SEO需要关注爬行?
爬行是搜索引擎理解并发现网页,并获取网页信息的环节。如果爬虫无法很好地爬行并解析网页的重要内容,那么你的网页可能无法被正常索引。而没有被索引的页面也是不可能获得任何排名的。
考虑到爬虫每天要访问几十甚至几百亿的页面,站长们肯定是想让自己的页面易于被爬行和抓取的,否则搜索引擎很有可能选择忽略你的页面,有价值的内容也不会被收录了。

之前提到的SEO技术方面(Technical SEO),很多时候是在处理网页的爬行/抓取问题,这就需要优化以下的方面:
- 清晰的网站的结构
- 网站外部和内部链接优化
- 用robots.txt文件控制爬虫爬行优先级高的页面,忽略低质量页面
- 用网站地图(sitemap)帮助爬虫快速发现网站所有页面
值得注意的是,之前提到过,爬虫初次来到网页时,抓取并解析的是网页的HTML代码,看到的页面类似于网页快照里的纯文字版本,而完整版本的页面需要后续经过渲染(rendering)才能被谷歌看到。
因次,我们要尽量避免把重要的内容(标题、描述、关键字等)放在Javascript中,否则搜索引擎爬虫可能无法正确抓取和理解这些内容。另外,如果你网页上某些链接需要执行Javascript才能被发现,那大概率这个链接不会被爬虫发现了。

总而言之,最好的做法是在网页的静态HTML中包含这些重要内容,因为HTML才是爬行环节会去抓取和解析的代码。还是那句话,爬虫每天真是有够忙的,我们需要帮助爬虫轻松发现网页,获取网页的重要信息,而不是给它添堵。这也是技术SEO需要解决的重要任务。
步骤二:索引/收录
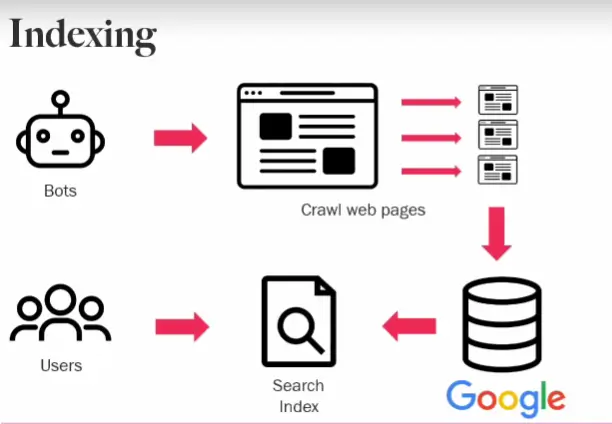
被爬虫访问和抓取的页面内容需要被组织并储存起来,建立一个包含各种页面信息的索引数据库。这个过程便是我们所说的索引/收录(indexing)。
当然,搜索引擎不会将页面上找到的所有信息都存储在索引中,它们只会储存必要的信息:内容创建/更新的时间、页面的标题、页面描述、页面的内容类型(文本、图片或者视频) 、和页面相关的关键字、链入和链出的链接(inlinks and outlinks)以及搜索引擎排名算法需要的许多其他参数。
这个收录的过程,其实也是排名的过程。更准确地说,是排名算法的准备过程。在索引阶段,搜索引擎会为每个网页计算一些基本的指标,如关键词出现频率、链接质量等。这些指标会在排名算法中用作初始数据。
这也是为什么当用户输入问题时,返回答案的速度快如闪电:搜索引擎的排名过程实际上是在用户输入查询之前就已经开始执行的,而用户输入的查询只是触发了排名算法的执行,并且最终呈现出排名结果给用户。
推荐阅读:
a.为什么SEO需要关注收录?
这个其实很好理解:如果你的网站不在谷歌的索引中,那就根本不会获得排名,别人搜任何问题都不可能发现你的网页。这也意味着编入索引的页面越多,出现在用户搜索结果中的机会就越大。
b.如何查询谷歌收录?
谷歌收录查询挺简单的,主要有两个方法:
1.在谷歌搜索栏用高级指令site:domain.com查询。注意site:www.domain.com和site:domain.com的结果可能是不同的,一个是查询www子域名下的页面,一个是查询根域名下所有的页面(如果是多语言站,包含了www和其它语言子域名)。
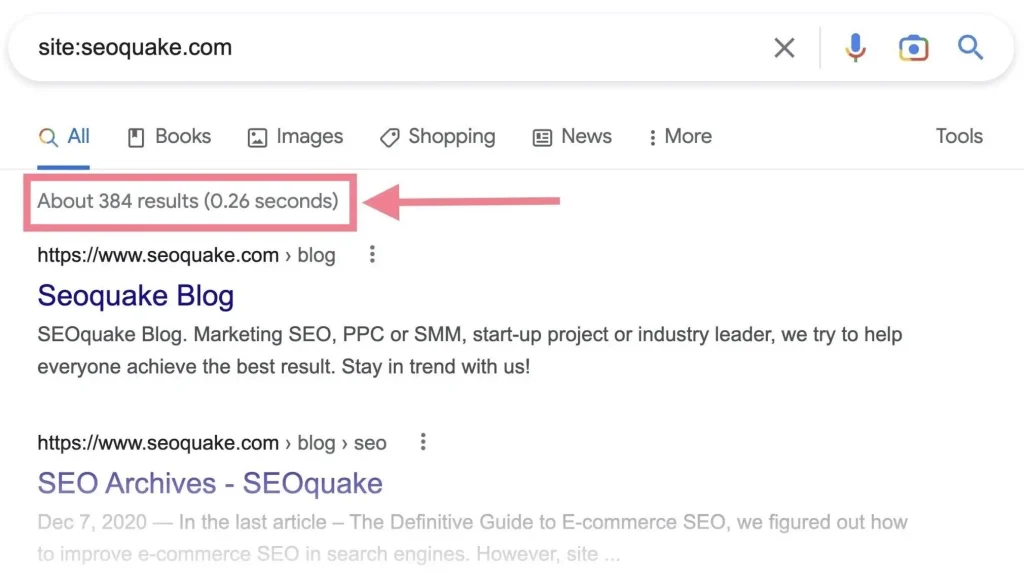
通过返回的搜索结果,你可以知道域名下大概有多少页面被收录。注意这个指令只是一个大致的统计,里面还包含了一些未被收录的页面。所以这个数据更多反映了谷歌知道的页面和数量,但这些页面不一定是都被收录的。
另外用高级指令在搜索栏查询还可以检查出网站的一些问题。比如页面收录数是否太少,是否数量爆炸(应该是遇到蜘蛛陷阱一类的问题了),是否收录了不想被收录的页面,收录的页面是否标题重复等等。
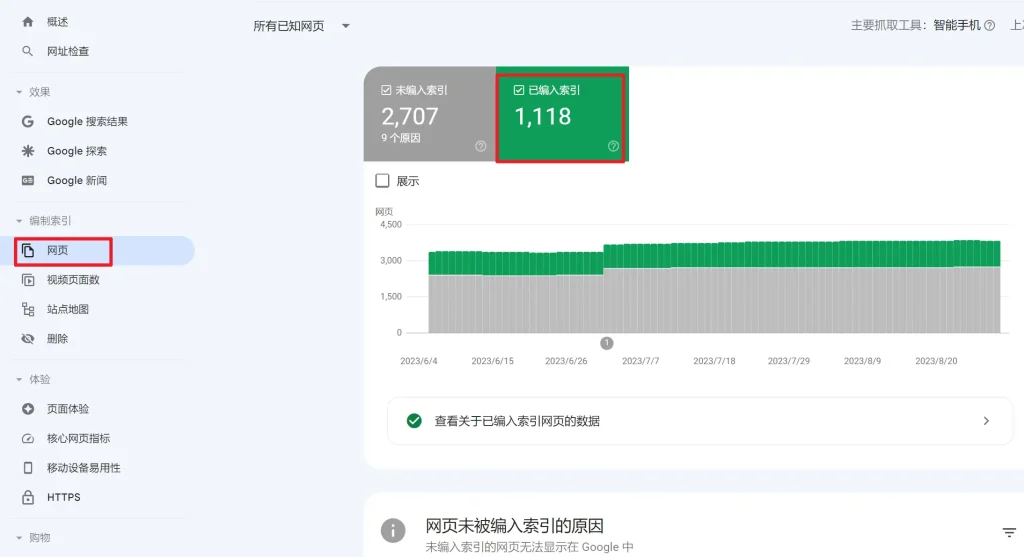
2.用GSC工具:想要知道准确的数据,最好还是用Google Search Console了,也就是我们说的谷歌站长工具。在站长工具内,点击“网页”,你就可以查看已编入索引的页面数。
c.什么样的页面不会被收录?
并不是所有被爬虫/蜘蛛爬行过的页面都会被编入索引。因为有些页面是无用的、低质量的,或者不能给用户带来太多价值的。其他一些不会被编入索引的页面包括:

- 隐私页面:包含个人信息、私人数据或受保护内容的页面。搜索引擎一般会尊重隐私,并避免收录此类页面。
- 登录页面: 需要登录才能访问的页面通常不会被收录,因为爬虫只会点击链接,无法进行登录这类复杂的用户交互行为。
- 重复内容: 如果页面内容与其他页面几乎完全相同,搜索引擎一般会选择不收录重复的内容。
- 标签页和分类页面: 一些网站上的标签页或者分类页面可能没有实际内容,只包含链接,因此搜索引擎可能会不收录这些页面(缺乏有价值的内容)。
- 被robots.txt 屏蔽的页面: 站长可以使用 robots.txt 文件来指示哪些页面不应该被爬行。爬行是搜索引擎工作的起点,不被爬行的页面自然也不会被收录了。
- 使用 “noindex” 标签的页面: 网页开发者可以通过在页面的 HTML 中添加 “noindex” 的元标签,告知搜索引擎不要收录该页面。另外即使是已收录的页面,加了noindex标签后搜索引擎也会选择把页面不收录。
- 动态生成的内容: 一些动态生成的内容可能对搜索引擎不可见,因为搜索引擎可能无法正确解析 JavaScript 或其他技术。这其实就是前面说的“需要避免把重要的内容放JS里“。
- 不受欢迎的内容: 搜索引擎可能会遵循法律规定,不收录包含不当内容(如违法、淫秽、仇恨性等)的页面。
d.什么是搜索引擎渲染(rendering)?
在收录过程中,还会有一个重要的过程:搜索引擎渲染。这玩意听上去高大上,其实就是谷歌通过加载html+css+Javascript,呈现出接近于浏览器加载页面的效果,从而完整地理解你网页内容的过程。

e.搜索引擎的渲染是什么时候开始的?
那渲染具体什么时候执行呢?一般来说是在抓取和索引过程之间,当然也有可能是索引以后后,毕竟CSS和Javascript的运行还是比较耗费谷歌资源的。
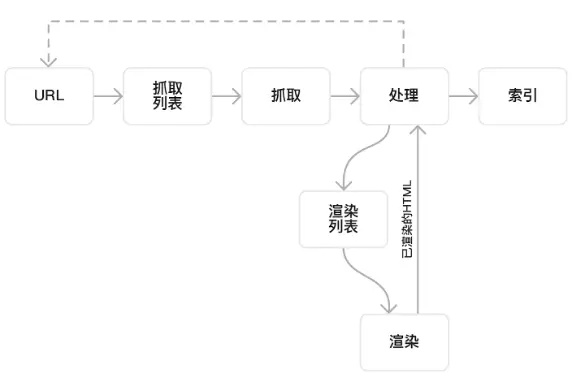
所以渲染时间也是不尽相同的。也许爬行后几小时就开始渲染了,也许页面收录了还没开始渲染,要再等几天或者几周。这也是为什么一些页面被收录了,但检查搜索引擎渲染情况是失败的。
这也是为什么在开发网页的过程中应当尽量减少JS的调用。很多企业为了使网站有更好的美观度,会在代码中调用大量的JS和Flash。但这可能会导致谷歌无法很好地理解你的网站内容。
f.如何查看页面是否被正确渲染?
主要有两种方法,一种是用网页快照,另一种是谷歌站长工具的URL检测:
1.网页快照:可以用来查看竞争对手的页面,因为你不可能有别人的站长工具权限。但是这种方法也有局限性,因为即使快照里显示为空页面,有时候也未必是渲染问题,有可能是浏览器安全性措施问题,这里不做赘述。另外网页快照也有一定的延后性,想要获得实时准确的信息还是要用站长工具检测。
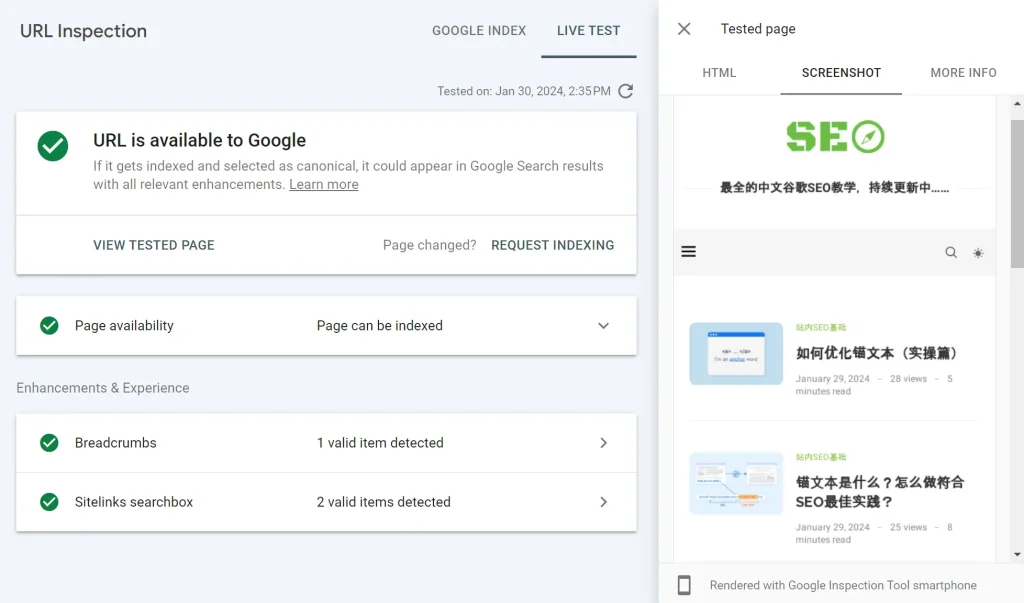
2.URL检测工具:在Google Search Console顶部里输入URL,点击“查看被抓取网页”- “屏幕截图”- “测试实际网址”就可以查看。
知航用自己博客首页做实验,点击”测试实际网址“,过了一分钟左右,主页是能够完整渲染的:
步骤三:排名
搜索引擎的排名过程并不是在用户输入问题的时候才开始的,实际上,搜索引擎的排名过程从爬取和索引阶段开始,并在用户输入查询之前就已经进行了很多处理。
a.谷歌排名的一般流程
以下是搜索引擎排名过程的一般流程:
爬取和索引: 在爬行阶段,爬虫会访问并抓取网页内容,然后将优质的页面进行收录,建立一个包含各种关键词、链接、内容片段等信息的索引数据库。
排名算法准备: 在索引阶段,谷歌会为每个网页计算一些基本的指标,如关键词出现频率、链接质量等。这些指标会在排名算法中用作初始数据。
用户查询输入: 当用户在搜索栏输入问题时,谷歌会收到这个查询并开始排名过程。
查询解析: 谷歌会解析用户的查询,分析其中的关键词和语义,理解用户的搜索意图。
排名算法执行: 排名算法会根据查询的关键词、语义、搜索历史等多个因素,结合之前建立的索引和网页指标,计算每个网页的相关性得分。这个得分决定了网页在搜索结果中的排名顺序。
排序和展示: 谷歌会按照计算得到的相关性得分对搜索结果进行排序,将最相关的网页排在前面。然后,这些排名好的结果将被呈现给用户。
需要注意的是,搜索引擎的排名算法是非常复杂的,并且可能涉及数百个信号和因素,如页面内容、链接质量、用户体验等。另外谷歌的算法会定期进行更新和优化。
所以,谷歌的排名过程实际上是在用户输入查询之前就已经开始执行的,而用户输入的查询只是触发了排名算法的执行,并最终呈现出排名结果给用户。
b.影响谷歌排名的重要因素
影响谷歌排名的因素有很多,目前已知的排名因素已经超过了255个,这里只展示一些知航认为重要的排名因素供参考:
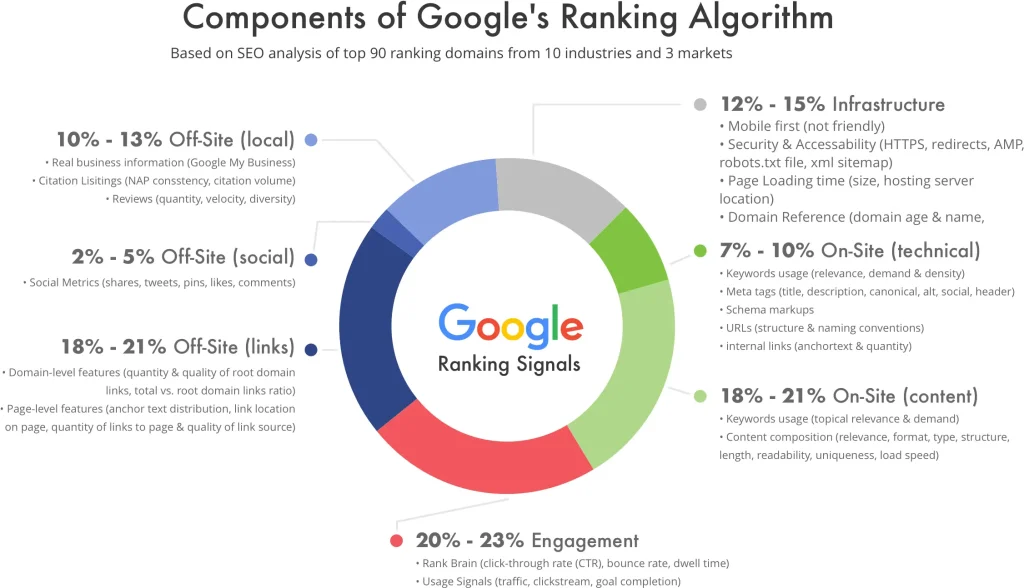
- 标题和内容相关性——页面的标题和内容与用户查询的相关性会对搜索排名产生很大的影响。
- 内容类型 – 这个很好理解,如果用户输入的问题中带关键词image,返回的结果将包含图像而不是文本。
- 内容的质量——内容必须全面、有用、信息丰富、不带有偏见。
- 网站的质量——网站的整体质量很重要。 Google 不会显示不符合其质量标准的网站页面。
- 发布日期 – 对于与新闻相关的查询,Google 希望显示最新结果,因此发布日期也会考虑在内。
- 页面的受欢迎程度——具有大量反向链接/外链(backlinks)的页面被认为比缺少外链的页面更受欢迎,排名算法也更有可能将其排在前面。
- 页面语言 – 这很好理解,谷歌肯定会优先将与用户输入语言一致的页面排在前面。
- 网页速度 – 加载速度快的网站(通常为 2-3 秒)与加载速度慢的网站相比具有一定优势。
- 设备类型 – 对于在移动设备上搜索的用户,谷歌将优先展示移动端适配的页面。
- 位置 – 用户搜索与自己所在地相关的问题 (比如“俄亥俄州的意大利餐馆”) 那谷歌会显示与用户所在地相关的结果。
知航也只是挪列了一些重要因素,而这些这只是冰山一角。 之前已经说过,Google 在算法中使用了超过 255 个因素对页面进行排名。可见谷歌的排名算法有多复杂了,而这也是为什么谷歌是世界上最受欢迎的搜索引擎 —— 始终用最先进的算法,为用户提供最准确,最优质的答案。
总结
好了,谷歌搜索原理就介绍到这里了。这篇文章的确写的有点长了。但是很完整地从爬行讲到渲染和收录,再讲到排名。如果你仔细阅读到结尾,应该能比较好地理解搜索引擎的基本原理了。
虽然这部分原理基本不涉及实操,但也是很重要的。尤其是SEO站内技术优化方面,之后理解原理后进行实操,你一定会受益匪浅。End.